
개요
스파크는 대규모 데이터를 빠르게 처리하기 위해 분산 처리 메커니즘을 갖춘 프레임워크이다. 스파크가 동작하는 원리를 이해하려면 Driver, Executor, Cluster Manager, 그리고 RDD, DAG, Job, Stage, Task 등 핵심 요소들을 살펴보아야 한다.
내용
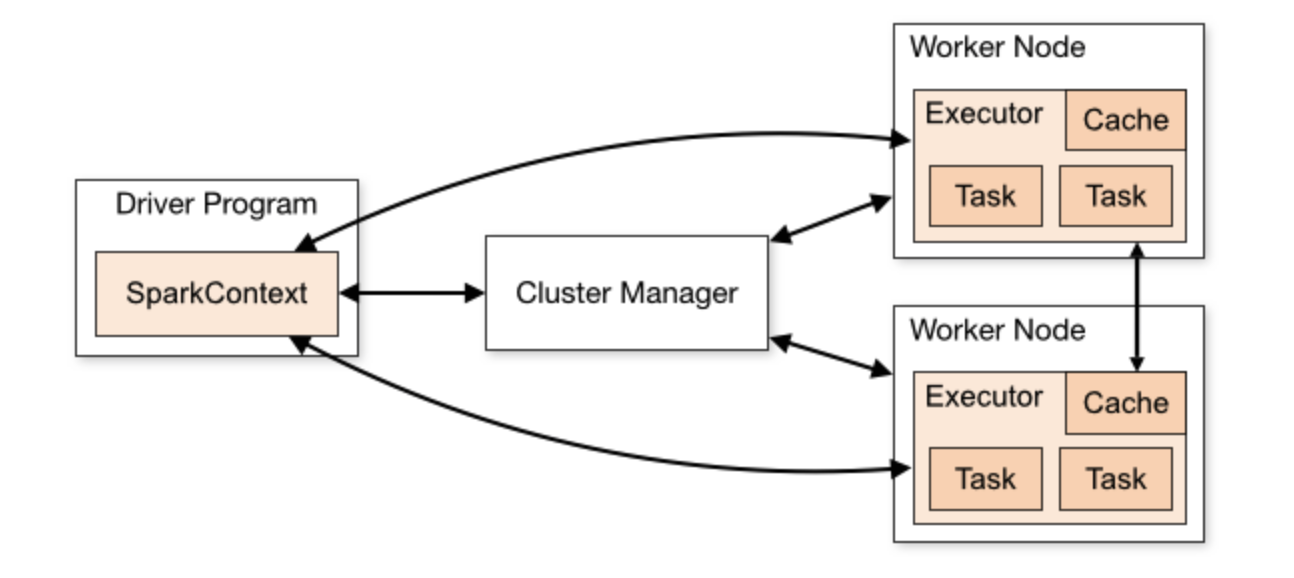
전체적인 아키텍처(Driver, Executor, Cluster Manager)
- Driver(드라이버) 는 사용자가 작성한 코드를 해석하고, 분산 작업을 지시·관리하는 주체이다.
- Executor(실행기) 는 Driver로부터 전달받은 작업을 실제로 수행하는 프로세스이며, 각 노드(Worker)마다 여러 Executor가 존재한다.
- Cluster Manager(클러스터 매니저) 는 Spark Standalone, YARN, Mesos, Kubernetes 등이 있다. 드라이버와 실행기에 필요한 리소스를 할당하고 전체 파이프라인을 관리한다.
RDD(Resilient Distributed Dataset)와 DAG(Directed Acyclic Graph)
스파크는 데이터를 추상화하기 위해 RDD라는 자료 구조를 사용한다.
- RDD는 파티션 단위로 분산 저장되는 불변(Immutable) 컬렉션이며, 장애가 발생해도 Lineage 정보를 통해 재생성할 수 있는 탄력성을 가진다.
- 사용자가 작성한 연산(트랜스포메이션)들은 내부적으로 DAG(Directed Acyclic Graph) 형태로 연결되며, 이를 기반으로 스파크는 최적화된 실행 경로를 결정한다.
병렬화된 컬렉션
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
외부 데이터 세트
JavaRDD<String> distFile = sc.textFile("data.txt");
Lazy Evaluation(지연 평가)
스파크는 Lazy Evaluation 방식을 통해 불필요한 연산을 줄이고 최적화를 수행한다.
- Transformation(map, filter, flatMap 등)은 즉시 실행되지 않고, 실행 계획에 반영만 된다.
- 자바 Stream과 상당히 유사하군?
- Action(count, collect, show 등)을 호출할 때, 그제서야 필요한 트랜스포메이션을 실제로 수행한다.
- 이로 인해 스파크는 전체 실행 계획을 종합적으로 분석하여 최소한의 연산만 수행할 수 있다.
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) { return s.length(); }
});
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});
Job, Stage, Task
스파크는 Action이 호출될 때마다 Job을 생성한다.
- 하나의 Job은 내부적으로 여러 Stage로 구분된다. Shuffle 연산이 일어나는 지점에서 스테이지가 나뉜다.
- 각 Stage는 다시 여러 개의 Task로 구성되며, RDD 파티션 단위로 병렬 처리를 수행한다.
셔플(Shuffle)
스파크에서 가장 비용이 큰 연산 중 하나가 Shuffle이다.
- 동일한 키를 가진 데이터끼리 연산하기 위해 reduceByKey, groupByKey, join 등에서 발생하며, 네트워크를 통한 재분배가 필요하다.
- 셔플이 발생할 때는 데이터의 파티션이 Executor들 간에 이동하므로, 실행 시간이 크게 늘어날 수 있다.
- 셔플 시점에서 Stage가 구분되므로, 셔플을 줄이는 전략이 성능 튜닝에 중요하다.
스파크 UI로 살펴보는 동작
스파크 애플리케이션을 실행하면 기본적으로 Spark UI(포트 4040) 에서 Job, Stage, Task, Executor 등의 정보를 모니터링할 수 있다.
- 각 Job별 실행 시간과 스테이지 구분, 셔플 발생 여부, 메모리 사용량 등을 확인 가능하다.
- 병목이 발생하는 부분이나 셔플이 과도하게 발생하는 지점을 파악하고, 튜닝 전략을 세울 수 있다.
참고 내용
Cluster Mode Overview - Spark 3.5.5 Documentation
Cluster Mode Overview This document gives a short overview of how Spark runs on clusters, to make it easier to understand the components involved. Read through the application submission guide to learn about launching applications on a cluster. Components
spark.apache.org
Submitting Applications - Spark 3.5.5 Documentation
Submitting Applications The spark-submit script in Spark’s bin directory is used to launch applications on a cluster. It can use all of Spark’s supported cluster managers through a uniform interface so you don’t have to configure your application esp
spark.apache.org
RDD Programming Guide - Spark 3.5.5 Documentation
RDD Programming Guide Overview At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed
spark.apache.org
Overview - Spark 3.5.5 Documentation
Downloading Get Spark from the downloads page of the project website. This documentation is for Spark version 3.5.5. Spark uses Hadoop’s client libraries for HDFS and YARN. Downloads are pre-packaged for a handful of popular Hadoop versions. Users can al
spark.apache.org
Job Scheduling - Spark 3.5.5 Documentation
Job Scheduling Overview Spark has several facilities for scheduling resources between computations. First, recall that, as described in the cluster mode overview, each Spark application (instance of SparkContext) runs an independent set of executor process
spark.apache.org
Tuning - Spark 3.5.5 Documentation
Tuning Spark Because of the in-memory nature of most Spark computations, Spark programs can be bottlenecked by any resource in the cluster: CPU, network bandwidth, or memory. Most often, if the data fits in memory, the bottleneck is network bandwidth, but
spark.apache.org
Web UI - Spark 3.5.5 Documentation
Web UI Apache Spark provides a suite of web user interfaces (UIs) that you can use to monitor the status and resource consumption of your Spark cluster. Table of Contents Jobs Tab The Jobs tab displays a summary page of all jobs in the Spark application an
spark.apache.org
'기술 탐구 > Spark' 카테고리의 다른 글
| (Apache Spark) Jupyter Notebook 환경에서 실습하는 Spark (0) | 2025.03.19 |
|---|
개요
스파크는 대규모 데이터를 빠르게 처리하기 위해 분산 처리 메커니즘을 갖춘 프레임워크이다. 스파크가 동작하는 원리를 이해하려면 Driver, Executor, Cluster Manager, 그리고 RDD, DAG, Job, Stage, Task 등 핵심 요소들을 살펴보아야 한다.
내용
전체적인 아키텍처(Driver, Executor, Cluster Manager)
- Driver(드라이버) 는 사용자가 작성한 코드를 해석하고, 분산 작업을 지시·관리하는 주체이다.
- Executor(실행기) 는 Driver로부터 전달받은 작업을 실제로 수행하는 프로세스이며, 각 노드(Worker)마다 여러 Executor가 존재한다.
- Cluster Manager(클러스터 매니저) 는 Spark Standalone, YARN, Mesos, Kubernetes 등이 있다. 드라이버와 실행기에 필요한 리소스를 할당하고 전체 파이프라인을 관리한다.
RDD(Resilient Distributed Dataset)와 DAG(Directed Acyclic Graph)
스파크는 데이터를 추상화하기 위해 RDD라는 자료 구조를 사용한다.
- RDD는 파티션 단위로 분산 저장되는 불변(Immutable) 컬렉션이며, 장애가 발생해도 Lineage 정보를 통해 재생성할 수 있는 탄력성을 가진다.
- 사용자가 작성한 연산(트랜스포메이션)들은 내부적으로 DAG(Directed Acyclic Graph) 형태로 연결되며, 이를 기반으로 스파크는 최적화된 실행 경로를 결정한다.
병렬화된 컬렉션
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
외부 데이터 세트
JavaRDD<String> distFile = sc.textFile("data.txt");
Lazy Evaluation(지연 평가)
스파크는 Lazy Evaluation 방식을 통해 불필요한 연산을 줄이고 최적화를 수행한다.
- Transformation(map, filter, flatMap 등)은 즉시 실행되지 않고, 실행 계획에 반영만 된다.
- 자바 Stream과 상당히 유사하군?
- Action(count, collect, show 등)을 호출할 때, 그제서야 필요한 트랜스포메이션을 실제로 수행한다.
- 이로 인해 스파크는 전체 실행 계획을 종합적으로 분석하여 최소한의 연산만 수행할 수 있다.
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) { return s.length(); }
});
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});
Job, Stage, Task
스파크는 Action이 호출될 때마다 Job을 생성한다.
- 하나의 Job은 내부적으로 여러 Stage로 구분된다. Shuffle 연산이 일어나는 지점에서 스테이지가 나뉜다.
- 각 Stage는 다시 여러 개의 Task로 구성되며, RDD 파티션 단위로 병렬 처리를 수행한다.
셔플(Shuffle)
스파크에서 가장 비용이 큰 연산 중 하나가 Shuffle이다.
- 동일한 키를 가진 데이터끼리 연산하기 위해 reduceByKey, groupByKey, join 등에서 발생하며, 네트워크를 통한 재분배가 필요하다.
- 셔플이 발생할 때는 데이터의 파티션이 Executor들 간에 이동하므로, 실행 시간이 크게 늘어날 수 있다.
- 셔플 시점에서 Stage가 구분되므로, 셔플을 줄이는 전략이 성능 튜닝에 중요하다.
스파크 UI로 살펴보는 동작
스파크 애플리케이션을 실행하면 기본적으로 Spark UI(포트 4040) 에서 Job, Stage, Task, Executor 등의 정보를 모니터링할 수 있다.
- 각 Job별 실행 시간과 스테이지 구분, 셔플 발생 여부, 메모리 사용량 등을 확인 가능하다.
- 병목이 발생하는 부분이나 셔플이 과도하게 발생하는 지점을 파악하고, 튜닝 전략을 세울 수 있다.
참고 내용
Cluster Mode Overview - Spark 3.5.5 Documentation
Cluster Mode Overview This document gives a short overview of how Spark runs on clusters, to make it easier to understand the components involved. Read through the application submission guide to learn about launching applications on a cluster. Components
spark.apache.org
Submitting Applications - Spark 3.5.5 Documentation
Submitting Applications The spark-submit script in Spark’s bin directory is used to launch applications on a cluster. It can use all of Spark’s supported cluster managers through a uniform interface so you don’t have to configure your application esp
spark.apache.org
RDD Programming Guide - Spark 3.5.5 Documentation
RDD Programming Guide Overview At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed
spark.apache.org
Overview - Spark 3.5.5 Documentation
Downloading Get Spark from the downloads page of the project website. This documentation is for Spark version 3.5.5. Spark uses Hadoop’s client libraries for HDFS and YARN. Downloads are pre-packaged for a handful of popular Hadoop versions. Users can al
spark.apache.org
Job Scheduling - Spark 3.5.5 Documentation
Job Scheduling Overview Spark has several facilities for scheduling resources between computations. First, recall that, as described in the cluster mode overview, each Spark application (instance of SparkContext) runs an independent set of executor process
spark.apache.org
Tuning - Spark 3.5.5 Documentation
Tuning Spark Because of the in-memory nature of most Spark computations, Spark programs can be bottlenecked by any resource in the cluster: CPU, network bandwidth, or memory. Most often, if the data fits in memory, the bottleneck is network bandwidth, but
spark.apache.org
Web UI - Spark 3.5.5 Documentation
Web UI Apache Spark provides a suite of web user interfaces (UIs) that you can use to monitor the status and resource consumption of your Spark cluster. Table of Contents Jobs Tab The Jobs tab displays a summary page of all jobs in the Spark application an
spark.apache.org
'기술 탐구 > Spark' 카테고리의 다른 글
| (Apache Spark) Jupyter Notebook 환경에서 실습하는 Spark (0) | 2025.03.19 |
|---|