
개요
데이터 엔지니어와 백엔드 개발자들이 자주 다루는 Apache Parquet 포맷은 일반적인 텍스트 데이터를 zip으로 압축한 것보다 훨씬 빠른 쿼리 성능을 보여준다. 이번 포스트에서는 Parquet가 왜 그렇게 빠른지, 열 지향(columnar) 구조가 어떤 원리로 쿼리 성능을 높이는지, 그리고 Parquet에서 사용되는 주요 압축 및 인코딩 기법들을 살펴보자. 또한 Trino, Spark, Hive 같은 분산 쿼리 엔진이 Parquet 데이터를 효율적으로 읽는 방법과, 일반 zip 압축 파일과 열 지향 압축 방식의 성능 차이도 비교해보자.
Parquet가 일반 Zip 압축보다 빠른 이유
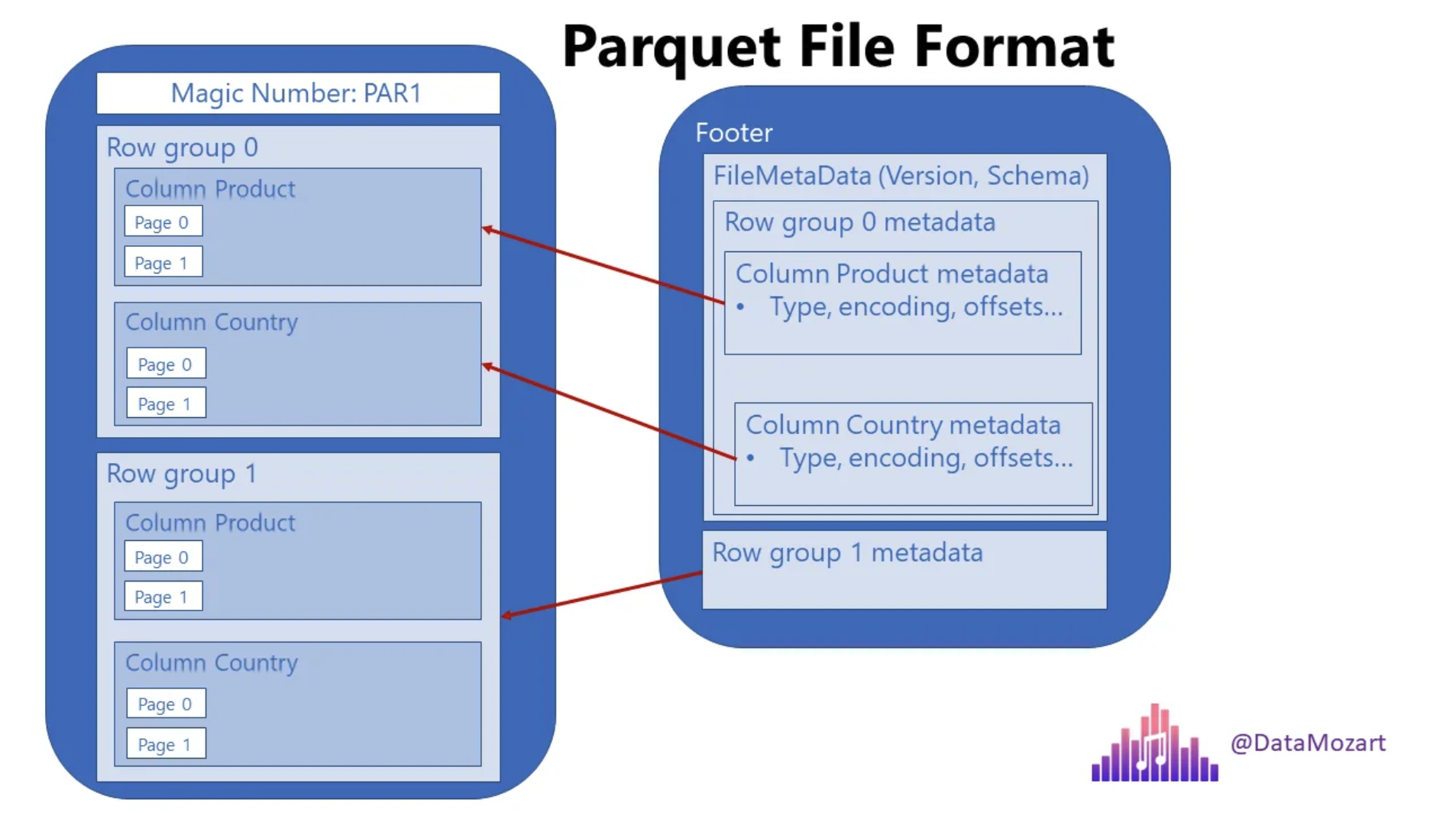
일반적인 zip 등의 파일 압축은 모든 데이터를 통째로 묶어 압축하는 반면, Parquet 포맷은 열 단위로 데이터를 저장하면서 압축한다. 이러한 구조적 차이 때문에 다음과 같은 성능 이점이 있다
- 부분 데이터 접근: Zip으로 압축된 CSV 같은 파일은 필요한 일부 데이터를 읽기 위해서도 전체 파일을 풀어서 읽어야 하는 경우가 많다. 반면 Parquet는 각 열(Column)을 독립적인 블록으로 저장하므로, 필요한 열만 선택적으로 읽고 압축 해제하면 된다. 예를 들어 100개 컬럼 중 10개만 필요한 쿼리라면, Parquet는 10개 컬럼에 해당하는 데이터만 디스크에서 읽지만, 압축된 CSV는 모든 컬럼 데이터를 한꺼번에 읽어야 하는 셈이다.
- 경량 압축 알고리즘 사용: Parquet는 기본 압축 코덱으로 Snappy 등을 사용한다. Snappy는 구글에서 개발한 알고리즘으로 빠른 압축/해제 속도를 자랑하며 실시간 쿼리에 적합하다. 반면 전형적인 zip 압축(Deflate 알고리즘, gzip과 유사)은 압축률은 높지만 속도가 느려 대용량 데이터를 실시간 분석하기엔 부적합하다. Parquet는 속도를 위해 약간의 추가 저장공간을 희생하고 Snappy 같은 코덱을 주로 사용하며, 필요에 따라 ZSTD 같이 빠른 해제와 높은 압축률을 모두 갖춘 최신 알고리즘도 지원한다
- 스플리터블(splittable) 포맷: Parquet 파일은 내부에 row group 단위로 쪼개져 있고, 각 row group 안의 열별 데이터가 별도 압축되기 때문에, 분산 환경에서 여러 작업자들이 파일을 나눠 병렬로 읽기에 용이하다. 반면 하나의 거대한 zip 파일은 병렬로 쪼개어 읽기 어렵다. 실제로 Hadoop 생태계에서는 Snappy로 압축된 Parquet 파일은 스플리터블로 간주되어 대용량 처리에 유리한 반면, gzip으로 압축된 텍스트 파일(CSV 등)은 그렇지 않다. 이 차이는 대규모 데이터 처리를 할 때 엄청난 성능 차이를 만든다.
요약하면, Parquet는 필요한 데이터만 최소한으로 읽고, 가벼운 압축 해제만 수행하기 때문에 zip보다 훨씬 빠르게 데이터를 스캔할 수 있다.
열 지향 포맷의 쿼리 성능 향상 원리
Parquet의 열 지향(columnar) 저장 방식은 쿼리 성능을 극대화하는 핵심 원리 중 하나이다. 그 구조적 장점을 살펴보자
- 필요한 열만 읽기 (프로젝션 푸시다운): 열 지향 포맷에서는 질의에 필요한 컬럼들만 연속적으로 저장되어 있으므로, 원하는 컬럼만 골라서 읽을 수 있다. 예를 들어 100개의 열 중 5개 열에 대해서만 집계 쿼리를 실행한다면, Parquet는 그 5개 열만 디스크 I/O로 읽으면 되므로 읽어야 할 데이터 양이 줄어든다. 반면 CSV같은 행 지향 포맷은 불필요한 열 데이터까지 모두 스캔해야 하므로 비효율적이다.
- 동종 데이터의 연속 저장: 같은 열의 값들은 타입과 패턴이 유사한 경우가 많다. Parquet는 한 컬럼의 모든 값을 인접하게 저장하기 때문에 데이터 패턴의 지역성이 높다. 이렇게 동질적인 데이터가 모여있으면 압축 효율이 더욱 높아지고 CPU 캐시 친화적인 접근이 가능해 쿼리 속도가 빨라진다. 예컨대 "성별"처럼 값이 반복되는 컬럼은 열 지향 저장 시 반복 패턴을 쉽게 압축하여 I/O 양을 크게 줄일 수 있다.
- 병렬 처리 최적화: 열 지향 파일은 컬럼 단위 또는 청크(chunk) 단위로 병렬 처리하기 좋다. 분산 SQL 엔진에서 Parquet 파일을 읽을 때, 하나의 큰 파일이라도 내부의 row group 단위로 여러 작업으로 나눠서 읽을 수 있고, 각 작업은 자신이 맡은 청크에서 필요한 컬럼만 취급한다. 그 결과 멀티스레드/멀티노드 병렬 읽기가 용이해져 전체 쿼리 처리 시간이 단축된다.
이러한 구조적 특징 덕분에 OLAP(Online Analytical Processing) 환경에서 Parquet는 CSV 등의 행 지향 포맷보다 훨씬 빠른 응답 시간을 보여준다. 열 지향 포맷은 데이터 웨어하우스/데이터 레이크에서 필수적인 형식으로 자리 잡았다.
Parquet의 주요 압축 및 인코딩 알고리즘
Parquet가 뛰어난 성능을 내는 비결 중 하나는 열별로 특화된 인코딩과 압축 알고리즘을 적용하기 때문이다. Parquet에서 사용되는 대표적인 기법들을 살펴보자
- 딕셔너리 인코딩(Dictionary Encoding): 컬럼 내에 중복된 값이 많을 때 효과적인 기법이다. 해당 열에서 유일한 값들의 사전(dictionary)을 만들고, 실제 데이터 값들을 그 사전의 참조(인덱스)로 치환하여 저장한다. 예를 들어 "부서명" 컬럼에 "영업", "마케팅" 같은 값들이 반복된다면, 각각의 값을 사전에 저장해 두고 본문에는 작은 정수 인덱스만 기록한다. 이렇게 하면 반복되는 문자열을 매번 저장하지 않아 공간이 절약되고, 후속 압축 알고리즘(Gzip이나 ZSTD 등)과 함께 사용하면 파일 크기를 크게 줄일 수 있다
- 런렝스 인코딩(RLE, Run-Length Encoding): 연속으로 반복되는 값을 압축하는데 뛰어난 방식이다. 동일한 값이 연속으로 나타나면, 그 값을 한 번만 저장하고 몇 번 반복됐는지 횟수만 저장하는 식이다. 예를 들어 100개의 연속된 행에서 "Status" 컬럼 값이 모두 "Active"라면, "Active"를 100번 쓰는 대신 "Active (100회)"로 기록하는 셈이다. 이렇게 **연속 중복이 많은 컬럼(예: 상태 플래그, Booleans 등)**에서 RLE는 큰 폭의 압축을 제공한다
- 비트 팩킹(Bit-Packing): 작은 정수 값을 저장할 때 사용되는 기법으로, 실제 값에 필요한 만큼의 비트 수만으로 데이터를 표현하는 것이다. 예를 들어 값 범위가 0~10인 열이 있다면 각 값을 32비트가 아닌 4비트로 표현하여 저장할 수 있다. 이렇게 하면 쓸데없는 0비트들을 없애므로 숫자 데이터를 효율적으로 압축할 수 있다
. Parquet는 비트-패킹과 RLE를 혼합한 하이브리드 인코딩을 사용하여, 데이터 분포에 따라 두 방식을 자동 전환해가며 최적의 압축을 이끌어낸다 - 스낵파이(Snappy): 앞서 언급했듯 Parquet에서 가장 많이 쓰이는 기본 압축 코덱이다. 압축률보다 속도에 초점을 맞춘 알고리즘으로, CPU 부하를 최소화하면서도 어느 정도 크기 감소를 달성한다. 실시간 분석 쿼리나 대화형 분석에 유리하며, Parquet의 기본 설정으로 많이 사용된다.
- 지스탠다드(ZSTD): ZSTD(Zstandard)는 페이스북(메타)에서 개발한 최신 범용 압축 알고리즘으로, 높은 압축률과 빠른 압축/해제 속도를 겸비하고 있다. Parquet에서도 지원되며, 튜닝에 따라 속도와 압축률을 조절할 수 있어 유연하다. 예를 들어 쿼리 성능이 중요하면 압축 레벨을 낮춰 빠른 해제를, 저장 공간 절약이 중요하면 압축 레벨을 높여 더 작은 파일 크기를 얻을 수 있다. ZSTD는 데이터 레이크 같이 저장 효율과 읽기 성능이 모두 중요한 환경에서 각광받고 있다
- 기타 코덱 (Gzip, Brotli, LZO 등): Parquet는 이 외에도 Gzip, Brotli, LZO 등의 압축을 지원한다. Gzip은 Deflate 알고리즘으로 압축률은 높지만 속도가 느려 빈번한 쿼리보다는 아카이빙 용도나 자주 읽지 않는 데이터에 적합하다. Brotli는 비교적 새로운 알고리즘으로 Gzip보다 더 높은 압축률을 내면서도 해제 속도가 빠른 편이라 읽기 성능과 용량 절약의 균형을 맞출 때 사용된다. LZO는 Snappy와 유사하게 매우 빠른 압축/해제를 제공하지만 압축률은 낮아, 실시간 스트리밍 처리 등 속도가 최우선인 경우에 쓰인다
분산 쿼리 엔진에서 Parquet의 구조적 장점 (Trino, Spark, Hive 등)
대용량 데이터를 처리하는 분산 SQL 엔진(예: Trino, Apache Spark, Apache Hive)은 Parquet 포맷의 구조를 최대한 활용하여 압축을 완전히 풀지 않고도 필요한 데이터만 빠르게 읽어들인다. 주요 구조적 장점을 정리하면
- 프레디킷 푸시다운(Predicate Pushdown): Parquet 파일은 메타데이터 영역에 각 컬럼의 통계 정보(최솟값, 최댓값 등)를 저장하고 있다. Spark나 Hive같은 엔진은 쿼리의 필터 조건을 이용해 Row Group 단위로 데이터를 건너뛸 수 있다. 예를 들어 WHERE 연도 = 2023 같은 조건이 있다면, 각 Row Group의 "연도" 컬럼 최솟값~최댓값 범위를 보고 2023이 전혀 없는 블록은 아예 읽지 않도록 스킵한다. 이는 해당 블록의 압축을 풀지 않고 통째로 뛰어넘는 최적화로, 대용량 데이터에서 엄청난 I/O 절감과 속도 향상을 가져온다.
- 컬럼 인덱스와 페이지 스킵: 최근 Parquet 포맷은 Row Group 내에서도 더 세밀하게 페이지(page) 단위의 컬럼 인덱스를 지원한다. Trino 등의 엔진은 이 컬럼 인덱스 정보를 활용하여 특정 페이지를 아예 읽지 않고 건너뛰는 최적화를 제공한다. 예컨대 수십만 개 행 중 조건에 맞는 값이 들어있을 법한 페이지들만 골라서 읽고, 나머지 페이지는 압축 해제는커녕 읽기조차 하지 않게 최적화할 수 있다. (Trino는 Hive Metastore 연동 시 parquet.use-column-index 설정을 통해 이 기능을 사용한다고 명시하고 있다
- 스캔의 최소화 & 지연된(deferred) 해제: 분산 엔진에서 Parquet를 읽을 때는 프로젝션 푸시다운(필요한 컬럼만 읽기)이 기본 적용된다. 읽어야 할 컬럼의 데이터 청크를 압축된 상태로 디스크에서 읽어 메모리로 가져온 뒤, 연산에 필요한 시점에만 풀어서 사용하거나, 벡터화된 방식으로 한 번에 해제하여 CPU 효율을 높인다. 예를 들어 Trino는 Java의 Vector API를 활용한 벡터화 디코딩으로 Parquet 읽기 성능을 높이고 있다. 요컨대 전체 데이터를 한꺼번에 풀지 않고, 필요한 조각만 골라 부분적으로 압축을 푸는 방식으로 동작한다.
이런 구조적인 장점들 덕분에, 분산 쿼리 엔진에서 Parquet 포맷은 디스크 I/O와 CPU 사용량을 최적화하여 매우 빠른 조회가 가능하다. Hive, Spark, Trino 등 여러 엔진에서 공통으로 Parquet를 채택하고 있으며, Parquet 메타데이터를 활용한 컬럼 단위의 스킵, 푸시다운 최적화는 엔진에 내장되어 있다
예를 들어 Spark의 경우 Parquet 파일을 읽을 때 물리적으로 일치하지 않는 Row Group은 아예 로드하지 않고(Min/Max를 이용한 푸시다운) 필요한 데이터만 읽어옴을 쿼리 플랜에서 확인할 수 있다. 이러한 최적화는 압축을 완전히 풀지 않고도 데이터를 선별하는 효과를 주어, 데이터 크기에 비해 훨씬 빠른 처리를 가능케 한다.
참고 자료
Apache Parquet vs AVRO: Open file formats, compute engine
Apache Parquet and Avro are open file formats that optimize different big data processing use cases. Both play a role in your open data lakehouse
www.starburst.io
All About Parquet Part 05 — Compression Techniques in Parquet
Free Copy of Apache Iceberg the Definitive Guide
medium.com
What are the pros and cons of the Apache Parquet format compared to other formats?
Some characteristics of Apache Parquet are: Self-describing Columnar format Language-independent In comparison to Apache Avro, Sequence Files, RC File etc. I want an overview of the formats. I have
stackoverflow.com
Encodings
Plain: (PLAIN = 0) Supported Types: all This is the plain encoding that must be supported for types. It is intended to be the simplest encoding. Values are encoded back to back. The plain encoding is used whenever a more efficient encoding can not be used.
parquet.apache.org
Spark – Reading Parquet – Predicate Pushdown for LIKE Operator – EqualTo, StartsWith and Contains Pushed Filters – Large
A Parquet file contains MIN/MAX statistics for every column for every row group that allows Spark applications to skip reading unnecessary data chunks depending on the query predicate. Let’s see how this works with LIKE pattern matching filter. For my te
cloudsqale.com
https://data-mozart.com/parquet-file-format-everything-you-need-to-know/
'컴퓨터 공학 > DB' 카테고리의 다른 글
| (RDB) recoverability schedule (0) | 2025.01.05 |
|---|---|
| (RDB) 트랜젝션이 동시에 실행될 때 isolation을 보장하는 기본 이론 (feat: schedule, serializability) (0) | 2025.01.04 |
개요
데이터 엔지니어와 백엔드 개발자들이 자주 다루는 Apache Parquet 포맷은 일반적인 텍스트 데이터를 zip으로 압축한 것보다 훨씬 빠른 쿼리 성능을 보여준다. 이번 포스트에서는 Parquet가 왜 그렇게 빠른지, 열 지향(columnar) 구조가 어떤 원리로 쿼리 성능을 높이는지, 그리고 Parquet에서 사용되는 주요 압축 및 인코딩 기법들을 살펴보자. 또한 Trino, Spark, Hive 같은 분산 쿼리 엔진이 Parquet 데이터를 효율적으로 읽는 방법과, 일반 zip 압축 파일과 열 지향 압축 방식의 성능 차이도 비교해보자.
Parquet가 일반 Zip 압축보다 빠른 이유
일반적인 zip 등의 파일 압축은 모든 데이터를 통째로 묶어 압축하는 반면, Parquet 포맷은 열 단위로 데이터를 저장하면서 압축한다. 이러한 구조적 차이 때문에 다음과 같은 성능 이점이 있다
- 부분 데이터 접근: Zip으로 압축된 CSV 같은 파일은 필요한 일부 데이터를 읽기 위해서도 전체 파일을 풀어서 읽어야 하는 경우가 많다. 반면 Parquet는 각 열(Column)을 독립적인 블록으로 저장하므로, 필요한 열만 선택적으로 읽고 압축 해제하면 된다. 예를 들어 100개 컬럼 중 10개만 필요한 쿼리라면, Parquet는 10개 컬럼에 해당하는 데이터만 디스크에서 읽지만, 압축된 CSV는 모든 컬럼 데이터를 한꺼번에 읽어야 하는 셈이다.
- 경량 압축 알고리즘 사용: Parquet는 기본 압축 코덱으로 Snappy 등을 사용한다. Snappy는 구글에서 개발한 알고리즘으로 빠른 압축/해제 속도를 자랑하며 실시간 쿼리에 적합하다. 반면 전형적인 zip 압축(Deflate 알고리즘, gzip과 유사)은 압축률은 높지만 속도가 느려 대용량 데이터를 실시간 분석하기엔 부적합하다. Parquet는 속도를 위해 약간의 추가 저장공간을 희생하고 Snappy 같은 코덱을 주로 사용하며, 필요에 따라 ZSTD 같이 빠른 해제와 높은 압축률을 모두 갖춘 최신 알고리즘도 지원한다
- 스플리터블(splittable) 포맷: Parquet 파일은 내부에 row group 단위로 쪼개져 있고, 각 row group 안의 열별 데이터가 별도 압축되기 때문에, 분산 환경에서 여러 작업자들이 파일을 나눠 병렬로 읽기에 용이하다. 반면 하나의 거대한 zip 파일은 병렬로 쪼개어 읽기 어렵다. 실제로 Hadoop 생태계에서는 Snappy로 압축된 Parquet 파일은 스플리터블로 간주되어 대용량 처리에 유리한 반면, gzip으로 압축된 텍스트 파일(CSV 등)은 그렇지 않다. 이 차이는 대규모 데이터 처리를 할 때 엄청난 성능 차이를 만든다.
요약하면, Parquet는 필요한 데이터만 최소한으로 읽고, 가벼운 압축 해제만 수행하기 때문에 zip보다 훨씬 빠르게 데이터를 스캔할 수 있다.
열 지향 포맷의 쿼리 성능 향상 원리
Parquet의 열 지향(columnar) 저장 방식은 쿼리 성능을 극대화하는 핵심 원리 중 하나이다. 그 구조적 장점을 살펴보자
- 필요한 열만 읽기 (프로젝션 푸시다운): 열 지향 포맷에서는 질의에 필요한 컬럼들만 연속적으로 저장되어 있으므로, 원하는 컬럼만 골라서 읽을 수 있다. 예를 들어 100개의 열 중 5개 열에 대해서만 집계 쿼리를 실행한다면, Parquet는 그 5개 열만 디스크 I/O로 읽으면 되므로 읽어야 할 데이터 양이 줄어든다. 반면 CSV같은 행 지향 포맷은 불필요한 열 데이터까지 모두 스캔해야 하므로 비효율적이다.
- 동종 데이터의 연속 저장: 같은 열의 값들은 타입과 패턴이 유사한 경우가 많다. Parquet는 한 컬럼의 모든 값을 인접하게 저장하기 때문에 데이터 패턴의 지역성이 높다. 이렇게 동질적인 데이터가 모여있으면 압축 효율이 더욱 높아지고 CPU 캐시 친화적인 접근이 가능해 쿼리 속도가 빨라진다. 예컨대 "성별"처럼 값이 반복되는 컬럼은 열 지향 저장 시 반복 패턴을 쉽게 압축하여 I/O 양을 크게 줄일 수 있다.
- 병렬 처리 최적화: 열 지향 파일은 컬럼 단위 또는 청크(chunk) 단위로 병렬 처리하기 좋다. 분산 SQL 엔진에서 Parquet 파일을 읽을 때, 하나의 큰 파일이라도 내부의 row group 단위로 여러 작업으로 나눠서 읽을 수 있고, 각 작업은 자신이 맡은 청크에서 필요한 컬럼만 취급한다. 그 결과 멀티스레드/멀티노드 병렬 읽기가 용이해져 전체 쿼리 처리 시간이 단축된다.
이러한 구조적 특징 덕분에 OLAP(Online Analytical Processing) 환경에서 Parquet는 CSV 등의 행 지향 포맷보다 훨씬 빠른 응답 시간을 보여준다. 열 지향 포맷은 데이터 웨어하우스/데이터 레이크에서 필수적인 형식으로 자리 잡았다.
Parquet의 주요 압축 및 인코딩 알고리즘
Parquet가 뛰어난 성능을 내는 비결 중 하나는 열별로 특화된 인코딩과 압축 알고리즘을 적용하기 때문이다. Parquet에서 사용되는 대표적인 기법들을 살펴보자
- 딕셔너리 인코딩(Dictionary Encoding): 컬럼 내에 중복된 값이 많을 때 효과적인 기법이다. 해당 열에서 유일한 값들의 사전(dictionary)을 만들고, 실제 데이터 값들을 그 사전의 참조(인덱스)로 치환하여 저장한다. 예를 들어 "부서명" 컬럼에 "영업", "마케팅" 같은 값들이 반복된다면, 각각의 값을 사전에 저장해 두고 본문에는 작은 정수 인덱스만 기록한다. 이렇게 하면 반복되는 문자열을 매번 저장하지 않아 공간이 절약되고, 후속 압축 알고리즘(Gzip이나 ZSTD 등)과 함께 사용하면 파일 크기를 크게 줄일 수 있다
- 런렝스 인코딩(RLE, Run-Length Encoding): 연속으로 반복되는 값을 압축하는데 뛰어난 방식이다. 동일한 값이 연속으로 나타나면, 그 값을 한 번만 저장하고 몇 번 반복됐는지 횟수만 저장하는 식이다. 예를 들어 100개의 연속된 행에서 "Status" 컬럼 값이 모두 "Active"라면, "Active"를 100번 쓰는 대신 "Active (100회)"로 기록하는 셈이다. 이렇게 **연속 중복이 많은 컬럼(예: 상태 플래그, Booleans 등)**에서 RLE는 큰 폭의 압축을 제공한다
- 비트 팩킹(Bit-Packing): 작은 정수 값을 저장할 때 사용되는 기법으로, 실제 값에 필요한 만큼의 비트 수만으로 데이터를 표현하는 것이다. 예를 들어 값 범위가 0~10인 열이 있다면 각 값을 32비트가 아닌 4비트로 표현하여 저장할 수 있다. 이렇게 하면 쓸데없는 0비트들을 없애므로 숫자 데이터를 효율적으로 압축할 수 있다
. Parquet는 비트-패킹과 RLE를 혼합한 하이브리드 인코딩을 사용하여, 데이터 분포에 따라 두 방식을 자동 전환해가며 최적의 압축을 이끌어낸다 - 스낵파이(Snappy): 앞서 언급했듯 Parquet에서 가장 많이 쓰이는 기본 압축 코덱이다. 압축률보다 속도에 초점을 맞춘 알고리즘으로, CPU 부하를 최소화하면서도 어느 정도 크기 감소를 달성한다. 실시간 분석 쿼리나 대화형 분석에 유리하며, Parquet의 기본 설정으로 많이 사용된다.
- 지스탠다드(ZSTD): ZSTD(Zstandard)는 페이스북(메타)에서 개발한 최신 범용 압축 알고리즘으로, 높은 압축률과 빠른 압축/해제 속도를 겸비하고 있다. Parquet에서도 지원되며, 튜닝에 따라 속도와 압축률을 조절할 수 있어 유연하다. 예를 들어 쿼리 성능이 중요하면 압축 레벨을 낮춰 빠른 해제를, 저장 공간 절약이 중요하면 압축 레벨을 높여 더 작은 파일 크기를 얻을 수 있다. ZSTD는 데이터 레이크 같이 저장 효율과 읽기 성능이 모두 중요한 환경에서 각광받고 있다
- 기타 코덱 (Gzip, Brotli, LZO 등): Parquet는 이 외에도 Gzip, Brotli, LZO 등의 압축을 지원한다. Gzip은 Deflate 알고리즘으로 압축률은 높지만 속도가 느려 빈번한 쿼리보다는 아카이빙 용도나 자주 읽지 않는 데이터에 적합하다. Brotli는 비교적 새로운 알고리즘으로 Gzip보다 더 높은 압축률을 내면서도 해제 속도가 빠른 편이라 읽기 성능과 용량 절약의 균형을 맞출 때 사용된다. LZO는 Snappy와 유사하게 매우 빠른 압축/해제를 제공하지만 압축률은 낮아, 실시간 스트리밍 처리 등 속도가 최우선인 경우에 쓰인다
분산 쿼리 엔진에서 Parquet의 구조적 장점 (Trino, Spark, Hive 등)
대용량 데이터를 처리하는 분산 SQL 엔진(예: Trino, Apache Spark, Apache Hive)은 Parquet 포맷의 구조를 최대한 활용하여 압축을 완전히 풀지 않고도 필요한 데이터만 빠르게 읽어들인다. 주요 구조적 장점을 정리하면
- 프레디킷 푸시다운(Predicate Pushdown): Parquet 파일은 메타데이터 영역에 각 컬럼의 통계 정보(최솟값, 최댓값 등)를 저장하고 있다. Spark나 Hive같은 엔진은 쿼리의 필터 조건을 이용해 Row Group 단위로 데이터를 건너뛸 수 있다. 예를 들어 WHERE 연도 = 2023 같은 조건이 있다면, 각 Row Group의 "연도" 컬럼 최솟값~최댓값 범위를 보고 2023이 전혀 없는 블록은 아예 읽지 않도록 스킵한다. 이는 해당 블록의 압축을 풀지 않고 통째로 뛰어넘는 최적화로, 대용량 데이터에서 엄청난 I/O 절감과 속도 향상을 가져온다.
- 컬럼 인덱스와 페이지 스킵: 최근 Parquet 포맷은 Row Group 내에서도 더 세밀하게 페이지(page) 단위의 컬럼 인덱스를 지원한다. Trino 등의 엔진은 이 컬럼 인덱스 정보를 활용하여 특정 페이지를 아예 읽지 않고 건너뛰는 최적화를 제공한다. 예컨대 수십만 개 행 중 조건에 맞는 값이 들어있을 법한 페이지들만 골라서 읽고, 나머지 페이지는 압축 해제는커녕 읽기조차 하지 않게 최적화할 수 있다. (Trino는 Hive Metastore 연동 시 parquet.use-column-index 설정을 통해 이 기능을 사용한다고 명시하고 있다
- 스캔의 최소화 & 지연된(deferred) 해제: 분산 엔진에서 Parquet를 읽을 때는 프로젝션 푸시다운(필요한 컬럼만 읽기)이 기본 적용된다. 읽어야 할 컬럼의 데이터 청크를 압축된 상태로 디스크에서 읽어 메모리로 가져온 뒤, 연산에 필요한 시점에만 풀어서 사용하거나, 벡터화된 방식으로 한 번에 해제하여 CPU 효율을 높인다. 예를 들어 Trino는 Java의 Vector API를 활용한 벡터화 디코딩으로 Parquet 읽기 성능을 높이고 있다. 요컨대 전체 데이터를 한꺼번에 풀지 않고, 필요한 조각만 골라 부분적으로 압축을 푸는 방식으로 동작한다.
이런 구조적인 장점들 덕분에, 분산 쿼리 엔진에서 Parquet 포맷은 디스크 I/O와 CPU 사용량을 최적화하여 매우 빠른 조회가 가능하다. Hive, Spark, Trino 등 여러 엔진에서 공통으로 Parquet를 채택하고 있으며, Parquet 메타데이터를 활용한 컬럼 단위의 스킵, 푸시다운 최적화는 엔진에 내장되어 있다
예를 들어 Spark의 경우 Parquet 파일을 읽을 때 물리적으로 일치하지 않는 Row Group은 아예 로드하지 않고(Min/Max를 이용한 푸시다운) 필요한 데이터만 읽어옴을 쿼리 플랜에서 확인할 수 있다. 이러한 최적화는 압축을 완전히 풀지 않고도 데이터를 선별하는 효과를 주어, 데이터 크기에 비해 훨씬 빠른 처리를 가능케 한다.
참고 자료
Apache Parquet vs AVRO: Open file formats, compute engine
Apache Parquet and Avro are open file formats that optimize different big data processing use cases. Both play a role in your open data lakehouse
www.starburst.io
All About Parquet Part 05 — Compression Techniques in Parquet
Free Copy of Apache Iceberg the Definitive Guide
medium.com
What are the pros and cons of the Apache Parquet format compared to other formats?
Some characteristics of Apache Parquet are: Self-describing Columnar format Language-independent In comparison to Apache Avro, Sequence Files, RC File etc. I want an overview of the formats. I have
stackoverflow.com
Encodings
Plain: (PLAIN = 0) Supported Types: all This is the plain encoding that must be supported for types. It is intended to be the simplest encoding. Values are encoded back to back. The plain encoding is used whenever a more efficient encoding can not be used.
parquet.apache.org
Spark – Reading Parquet – Predicate Pushdown for LIKE Operator – EqualTo, StartsWith and Contains Pushed Filters – Large
A Parquet file contains MIN/MAX statistics for every column for every row group that allows Spark applications to skip reading unnecessary data chunks depending on the query predicate. Let’s see how this works with LIKE pattern matching filter. For my te
cloudsqale.com
https://data-mozart.com/parquet-file-format-everything-you-need-to-know/
'컴퓨터 공학 > DB' 카테고리의 다른 글
| (RDB) recoverability schedule (0) | 2025.01.05 |
|---|---|
| (RDB) 트랜젝션이 동시에 실행될 때 isolation을 보장하는 기본 이론 (feat: schedule, serializability) (0) | 2025.01.04 |