
개요
URL 단축(URL Shortening) 서비스는 긴 URL을 짧은 형태로 변환해주는 웹 서비스이다. 예를 들어, https://example.com/very/long/pathasdasdasd 같은 URL을 https://tinyurl.com/2ee6n3sn처럼 훨씬 짧은 주소로 바꾸어준다. 이렇게 생성된 단축 URL을 클릭하면 원래의 긴 URL로 리디렉션된다. 대표적인 예로 TinyURL이나 Bitly 등이 있으며, 트위터와 같이 글자 수 제한이 있는 플랫폼에서 인기를 끌었다. 이러한 서비스는 긴 URL을 짧게 공유하기 쉽게 만들어주고, 데이터베이스에 그 매핑 정보를 저장하여 사용자의 접근 시 원래 주소로 안내해준다. 이제 이러한 URL Shortener 서비스를 설계하는 방법에 대해 단계별로 살펴보자.
설계 고려 사항
URL 단축 서비스를 설계하기 위해 먼저 요구사항을 정의하고, 시스템 규모를 추정한 뒤, 트래픽 특성(Read Heavy vs Write Heavy)을 고려해야 한다. 이후 이를 바탕으로 전체 시스템 아키텍처와 데이터베이스 구성을 결정한다. 마지막으로 URL을 단축하는 알고리즘 (해시 기반 또는 카운터 기반)을 선택하고, 각 접근법의 장단점을 살펴본다. 아래에서 이 과정을 순서대로 설명해보자.
기능 및 비기능 요구사항 정리
기능적 요구사항 (Functional Requirements)
- 단축 URL 생성: 사용자가 긴 원본 URL을 보내면, 시스템은 고유한 짧은 URL을 생성하여 반환해야 한다. 예를 들어 입력으로 https://www.example.com/...를 주면 출력으로 abcd123와 같은 짧은 코드 또는 전체 단축 URL을 제공한다.
- 리디렉션 기능: 사용자가 단축 URL로 접속하면, 해당 코드에 대응되는 원본 URL로 빠르게 리디렉션해주어야 한다 (HTTP 301/302 리다이렉트 응답).
- 중복 처리: 동일한 긴 URL에 대해 항상 같은 단축 URL을 반환할지 여부를 결정해야 한다. (예: 이미 존재하는 URL을 다시 단축 요청 시 기존 코드를 재사용하거나 새 코드를 생성할 수 있다.)
- 선택적 부가 기능: 필요에 따라 사용자 지정 alias 지원(예: 사용자가 원하는 단축코드 지정)이나 단축 URL 만료기능(일정 기간 후 비활성화), 클릭 수 집계 등의 부가기능을 고려할 수 있다. (기본 설계에서는 없지만 확장 가능 요소로 언급).
비기능적 요구사항 (Non-Functional Requirements)
- 확장성 (Scalability): 서비스는 대량의 URL 생성 요청과 훨씬 더 많은 리디렉션 트래픽을 처리할 수 있어야 한다. 추후 사용자 및 데이터 증가에 따라 수평 확장이 가능하도록 설계해야 한다.
- 가용성 (Availability): 단축 URL은 한 번 생성되면 항상 유효해야 한다. 시스템 장애나 데이터 손실 없이 24/7 서비스를 제공하도록, 특히 데이터베이스의 내구성(Durability)과 백업/복제 전략이 필요하다.
- 성능 (Performance): 단축 URL 생성 요청은 짧은 시간 내 처리되어야 하고, 생성된 URL을 통한 리디렉션은 매우 낮은 지연으로 이루어져야 한다. 예를 들어, 단축 URL 리디렉션은 사용자 입장에서 거의 실시간으로 원본 페이지에 연결되도록 해야 한다.
- 읽기/쓰기 최적화: URL 단축 서비스는 일반적으로 읽기 요청(리디렉션)이 쓰기 요청(새 URL 생성)보다 훨씬 많다. 따라서 읽기 성능 최적화(예: 캐싱, 복제)를 특히 신경 써야 한다. 반면 쓰기 또한 일정 수준 이상 발생하므로 쓰기도 안정적으로 처리할 수 있어야 한다.
- 보안 및 악용 방지: 생성된 단축 URL이 예측 가능하면 임의의 단축코드를 추측해 원본 URL을 열어보는 브루트포스 공격이 가능하다. 따라서 단축 코드의 예측 가능성을 낮추거나 필요한 경우 접근 통제를 고려해야 한다. 또한 악성 URL의 단축 등 보안 모니터링도 요구될 수 있다.
시스템 규모 추정(간단한 데이터 계산)
설계를 구체화하기 위해, 예상되는 시스템 규모를 나이브하게 추산해보자.
예를 들어 월간 100백만 건의 URL 단축 요청이 발생한다고 가정해보자.
이는 일평균 약 333만 건, 초당 약 40건의 쓰기 요청에 해당한다.
반면 리디렉션(읽기) 요청은 이보다 훨씬 많을 수 있다. 읽기/쓰기가 100:1 비율이라고 가정하면, 월 100백만 건의 생성에 대해 100억 건의 리디렉션이 발생할 수 있다.
이는 일평균 약 3.3억 건, 초당 약 3,800건의 읽기 요청이다. 실제로 트래픽은 균일하지 않고 특정 단축 URL이 폭증하는 경우도 있는데, 인기 있는 단축 링크 하나가 초당 수천 건의 접근을 유발할 수도 있다. 이러한 수치를 통해 읽기 성능이 얼마나 중요한지 알 수 있다.
데이터 저장 용량도 계산해보자. 위 가정대로라면 1년에 약 12억 개의 URL이 축적된다. 5년이면 60억 개에 달한다. 각 URL 매핑(짧은 코드 + 원본 URL)을 저장하는 데 평균 200 바이트를 사용한다고 하면 (원본 URL 길이 등에 따라 다르지만 메타데이터 포함 가정), 60억 * 200B ≈ 1.2TB 정도의 저장공간이 필요하다. 만약 규모가 더 커져 10년간 600억 개를 저장한다면 약 12TB가 필요하다. 따라서 수십억 건의 레코드와 테라바이트급 데이터를 다룰 수 있는 저장소가 필요함을 알 수 있다.
또한 단축 URL의 코드 길이를 결정해야 한다. 사용할 문자의 종류에 따라 가능한 조합 수가 달라지는데, 일반적으로 영대소문자 + 숫자를 사용하여 **62진법(Base62)**으로 표현한다. 이 경우 길이가 n인 단축코드는 최대 62^n 가지 조합을 갖는다. 예를 들어 6자리일 경우 62^6 ≈ 56.8억 가지, 7자리일 경우 62^7 ≈ 3.5조(3.5 trillion) 가지 조합을 만들 수 있다.
앞서 추산한 필요량(수십억~수백억 수준)에 비춰보면, 6자리로도 수년 치를 커버할 수 있으나 서비스 수명이 길어지거나 사용량이 늘면 부족할 수 있다. 7자리로 하면 이론적으로 수조 개의 URL까지 표현 가능하므로 향후 여유를 두고 7자리로 결정하는 것이 안전해보인다 (예: 7자리면 초당 1,000개씩 만들어도 100년간 약 3.1조 개 생성 가능
Read Heavy vs Write Heavy 판단
앞서 언급했듯, URL 단축 서비스 트래픽은 읽기(Read) 요청이 압도적으로 많은 Read-Heavy 형태이다. Write-Heavy 시스템이 아니라는 점이 중요하다.
다시 말해 새로운 단축 URL을 생성하는 쓰기 작업도 지속적으로 발생하지만, 이미 생성된 단축 URL로 접속하는 읽기 작업의 빈도가 훨씬 높다. 예를 들어, 하나의 단축 URL이 생성되면 여러 사용자가 반복해서 접근하므로 1회 쓰기 후 N회 읽기 패턴이 일반적이다 (N이 매우 큰 값). 실제 비율은 서비스 특징에 따라 10:1에서 1000:1까지 차이가 있을 수 있지만, 설계 시 읽기 최적화에 중점을 두는 게 바람직하다.
이러한 특성에 따라 캐싱 전략과 데이터베이스의 읽기 성능이 중요해진다. 자주 요청되는 단축 URL 매핑은 메모리 캐시(예: Redis와 같은 인메모리 키-값 저장소)에 저장해 DB 부하를 줄일 수 있다. 또한 DB 복제를 통해 여러 리플리카에서 읽기 트래픽을 분산 처리하는 것도 고려된다. 반면 쓰기 성능은 상대적으로 여유가 있지만, 충분한 수평 확장성을 확보하여 피크 시에도 생성 요청을 처리할 수 있어야 한다. 요약하면 이 서비스는 읽기 최적화된 설계가 핵심이며, 쓰기 경로도 안정적으로 뒷받침해야 한다.
초기 시스템 구조
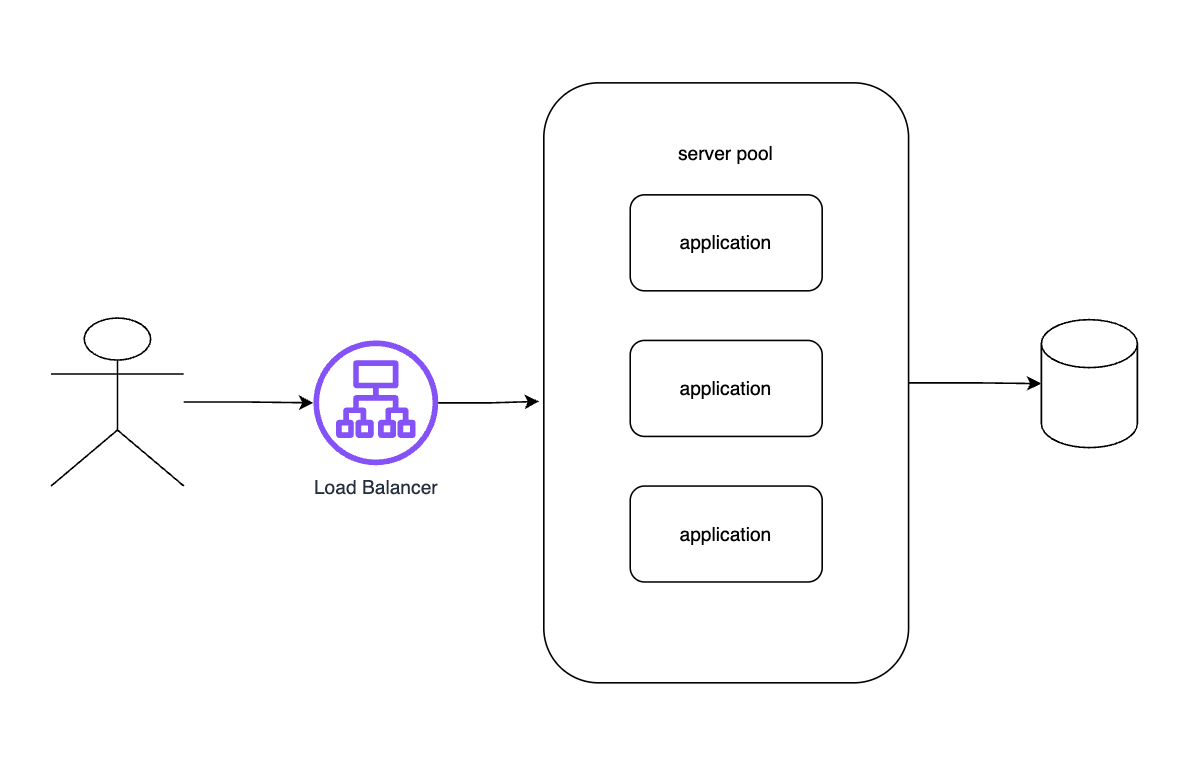
초기 시스템 아키텍처를 간략히 구성해보자. 기본 구성 요소는 로드 밸런서(Load Balancer), 애플리케이션 서버(서버 풀), 그리고 데이터베이스로 이루어진다. 클라이언트(웹 브라우저 또는 모바일 앱)가 단축 URL 요청을 보내면, 로드 밸런서가 다수의 애플리케이션 서버 중 한 대로 트래픽을 분산시킨다. 애플리케이션 서버는 다음과 같은 역할을 한다:
- 신규 단축 URL 생성 요청 처리: 긴 URL을 입력 받아, 짧은 코드를 생성하고 DB에 저장한 후 사용자가 사용할 수 있게 반환한다.
- 리디렉션 요청 처리: 들어온 단축 URL 코드에 해당하는 원본 URL을 DB에서 조회하고, HTTP 리디렉트 응답을 보내 사용자 브라우저를 원래 주소로 돌려보낸다.
스키마 설계
URL 단축 서비스의 데이터베이스에는 기본적으로 “짧은 코드”와 “원본 URL”의 매핑을 저장하는 테이블이 필요하다. 이를 설계해보자. 단순한 형태의 스키마는 다음과 같다

- ShortCode (단축 코드): 문자열 or 정수 형태의 고유 키. 예: "abc123"와 같은 짧은 문자열 코드. 이 컬럼을 PRIMARY KEY로 지정한다 (고유한 값이어야 함).
- OriginalURL (원본 URL): 장문의 원래 URL 문자열. 일반적으로 가변 길이 문자열(VARCHAR 또는 TEXT)로 저장한다.
- CreatedAt (생성 시각): URL이 단축된 시간 타임스탬프 (Optional, 나중에 통계나 만료 기능에 활용 가능).
- ExpiresAt (만료 시각): 단축 URL이 만료될 시간 (Optional, 만료 기능이 있을 경우).
- ClickCount (조회 수): 해당 단축 URL이 몇 번 클릭되었는지 (Optional, 트래킹 기능이 있다면).
기본적인 동작에는 ShortCode와 OriginalURL 두 필드만으로 충분하다. ShortCode를 기본키로 설정하면 데이터베이스가 자동으로 이 컬럼에 인덱스를 만들어주므로, 단축 URL로 원본 URL을 빠르게 조회(O(1) 조회)할 수 있다. OriginalURL 컬럼에도 필요에 따라 인덱스를 걸 수 있는데, 동일한 원본 URL에 대한 중복 삽입을 방지하거나 검색하려는 경우가 아니면 굳이 인덱싱하지 않아도 된다.
SQL vs NoSQL 비교 및 선택
다음으로 데이터베이스로 SQL(관계형)을 사용할지 NoSQL(비관계형)을 사용할지 선택해야 한다. 둘의 장단점을 이 서비스 관점에서 비교해보자
- SQL 기반 (예: MySQL, PostgreSQL 등):
관계형 데이터베이스는 강력한 일관성(ACID 트랜잭션)과 복잡한 쿼리 기능을 제공한다. 우리의 서비스에서는 대부분 단순 키-값 조회지만, 관계형 DB를 쓰면 자동 증가 시퀀스 등을 활용해 단축 코드 생성을 쉽게 관리할 수 있고, 고유 제약(unique constraint)을 통해 중복 방지도 손쉽게 할 수 있다.
초기 소규모 시스템에서는 하나의 RDB로도 충분하며, 익숙한 SQL을 사용해 개발 생산성이 높다. 하지만 데이터가 수십억 건으로 커지면 수직 확장(vertical scaling) 한계에 부딪힐 수 있고, 샤딩 구현의 복잡성이 있다. 또한 높은 QPS를 처리하려면 복제와 분산이 필요한데, 전통적인 RDBMS는 수평 확장(horizontal scaling)이 어려운 편이다. - NoSQL 기반 (예: Cassandra, DynamoDB, MongoDB 등)
비관계형 데이터베이스(특히 키-값 저장소나 컬럼 패밀리 DB)는 단순 조회에 최적화되어 있고, 데이터가 커져도 노드 추가를 통한 수평 확장이 용이하다. 우리의 주요 연산인 "ShortCode로 OriginalURL 찾기"는 키 기반 조회로, NoSQL의 접근 패턴과 잘 맞는다.
NoSQL은 스키마가 유연하고, 대용량 데이터 분산 저장에 강점이 있다. 다만 조직된 복잡한 쿼리나 JOIN 등이 필요하면 어려우며, 일관성 모델이 RDB와 다를 수 있다 (기본적으로 eventual consistency를 택하는 시스템도 있다). 우리 서비스의 경우 관계형 쿼리가 많지 않고(대부분 단순 get/set) NoSQL이 확장에 더 유리할 것으로 판단된다.
선택: 초기 구현 단계에서는 데이터량이 많지 않다면 관계형 DB로 시작하는 것도 괜찮다. 예컨대 MySQL에 위 스키마대로 테이블 하나 놓고 쓰면서, AUTO_INCREMENT PK를 이용해 단축 ID를 생성하면 편리하다. 그러나 서비스 규모가 커질 것을 대비한다면 애초에 분산형 NoSQL을 사용하는 것이 확장성과 성능 면에서 유리하다. 실제로 많은 URL Shortener 서비스가 내부적으로 분산 키-값 저장소를 사용한다. 요약하면, 초기엔 SQL로 간단히, 성장 시 NoSQL로 마이그레이션하거나, 요구 트래픽 수준에 따라 곧바로 NoSQL을 채택할 수 있다.
해시 함수 기반 솔루션
이제 짧은 URL 코드를 생성하는 구체적인 방법을 살펴보자. 여러 가지 방법이 있지만, 크게 두 가지 접근 방식이 널리 논의된다
- 해시 함수 기반 방법 – 입력 URL의 해시값을 이용하여 코드를 만드는 방법
- 카운터 기반 방법 – 전역 증가 숫자를 이용하여 코드를 만드는 방법
먼저 해시 함수(Hash Function)를 사용하는 방안을 검토한다.
해시 기반 방법은 입력 값으로부터 고정 길이의 난수화된 출력을 생성하는 해시 함수의 성질을 이용한다. 예를 들어 MD5, SHA-1, SHA-256 같은 해시 알고리즘은 임의의 길이의 입력을 넣으면 거의 균일하게 분포된 큰 수(해시값)를 출력해준다. 이 해시값을 우리가 원하는 단축 코드 길이에 맞게 Base62 등으로 변환하여 사용하면 된다. 이 접근의 장점은 입력만으로 출력이 정해지므로 별도의 상태 관리 없이도 코드를 만들 수 있고, 동일한 긴 URL에 대해서는 항상 같은 단축 결과를 얻을 수 있다는 점이다.
Base62 인코딩 개념
해시값을 직접 문자열로 쓰기에는 너무 길고 읽기 어려우므로, 일반적으로 Base62 인코딩을 사용해 사람이 읽을 수 있는 짧은 문자열로 변환한다. Base62는 말 그대로 62진법으로 숫자를 표현하는 방식인데, 0-9, A-Z, a-z 총 62개의 문자로 숫자를 나타낸다. 예를 들어 10진수 61은 Base62로 z (마지막 문자)이며, 62는 자릿수가 올라가 10 (두 자리)로 표현된다. 즉, 62를 넘는 숫자는 자릿수를 늘려가며 표현한다. Base62 인코딩을 사용하면 같은 숫자를 더 적은 문자로 표현할 수 있어서 단축 URL에 적합하다.
Base62로 표현할 수 있는 조합 수는 앞서 언급했듯이 자릿수에 따라 62^n 이 된다. 7자리라면 62^7 ≈ 3.5조의 조합을 커버할 수 있다. 해시 함수가 만들어내는 큰 숫자를 이 62진법으로 변환하면 보통 7자보다 훨씬 긴 문자열이 나오기 때문에, 일부만 잘라서 사용하게 된다. (Base62 자체는 인코딩/디코딩 알고리즘이 정해져 있지만 여기서는 개념적으로 숫자를 문자열로 변환하는 과정이라고 이해하면 된다.)
첫 번째 솔루션: MD5 해시 -> Base62 방식
MD5 기반 단축 알고리즘을 예로 들어보자. MD5는 입력값에 대해 128비트 길이의 해시 값을 출력한다. 이 128비트 정수를 그대로 62진법 문자로 나타내면 약 21~22자리의 문자열이 된다. 하지만 우리가 정한 단축 코드 길이는 예를 들어 7자리이므로, 이 해시 결과를 7글자만 사용하도록 줄여야 한다. 가장 간단한 방법은 해시값(Base62 문자열)의 앞부분 7글자만 취하는 것이다
- 입력 URL에 MD5 해시 함수를 적용 -> 128-bit 해시 생성.
- 그 해시 값을 62진수 문자로 표현 -> 예: "25AJC1pA6Z..."처럼 20자 넘는 문자열이 나왔다고 하자.
- 앞에서 정한 길이만큼만 자른다 -> "25AJC1p" (앞 7글자) 를 단축 코드로 사용.
예를 들어, http://example.com/test라는 URL을 MD5 해싱하고 Base62로 변환하면 "25AJC1pA6Z..." 와 같은 문자열이 나올 수 있다. 여기서 앞 7자리 "25AJC1p"를 단축 코드로 저장하는 식이다.
이렇게 하면 일단 겉보기에 무작위성 있는 고정 길이 코드가 생성된다. 해시 함수 덕분에 입력이 조금만 달라도 출력이 완전히 달라지므로, URL이 유사해도 단축 코드는 충돌하지 않도록 잘 퍼져나간다. 또한 해시 계산은 로컬에서 빠르게 수행될 수 있어, 별도의 중앙 집중식 ID 발급 과정을 거치지 않고도 각 앱 서버가 동시에 단축 코드 생성을 할 수 있다.
그러나, 이 방법에는 중요한 문제가 있다. 바로 해시 충돌(hash collision)이다. 해시 함수 자체는 매우 큰 출력 공간(2^128 등)을 가지므로 서로 다른 입력이 같은 해시값을 낼 확률은 무척 낮지만, 우리는 그 해시의 일부분(7글자)만 사용하기 때문에 실제 충돌 가능성은 무시할 수 없게 된다. 7글자 Base62 문자열 공간은 약 3.5조 개로 매우 크지만, 이 서비스가 장기간 운영되며 전세계적으로 사용된다면 언젠가 충돌이 일어날 가능성이 존재한다. 특히 서로 다른 두 URL이 우연히 같은 7자리 코드를 갖게 되면 큰 문제이다 (하나는 다른 URL로 가리켜야 하는데 충돌로 인해 잘못 매핑됨).
해시 충돌 문제 및 대응 방안
해시 기반 방식에서는 충돌을 처리하는 로직이 필수적이다. 기본 아이디어는 "만약 새로운 단축 코드를 만들었는데 이미 DB에 존재한다면, 그것이 다른 URL인지 확인하고 충돌이라면 다른 코드를 다시 생성"하는 것이다. 구체적인 대응 방안은 몇 가지가 있다
- DB 중복 체크 및 재해시(re-hash): 단축 코드 테이블에서 해당 코드(short_code)가 이미 존재하는지 조회한다. 존재하지 않으면 그대로 사용하고, 이미 존재한다면 그것이 같은 OriginalURL인지 확인한다. 만약 다른 URL과 충돌한 경우, 같은 해시 알고리즘에 조금 다른 입력을 넣어 새로운 코드를 시도한다. 예를 들어, 원본 URL에 어떤 임의의 문자열(또는 증가하는 숫자)를 붙여 다시 해시를 구하고, 새로운 코드를 생성한다. 이것을 충돌이 해결될 때까지 반복한다. 해시 공간이 크기 때문에 한 번 충돌이 일어난다고 연속으로 충돌할 확률은 극히 적다.
- 해시 길이 연장: 처음부터 7자 코드로 잘랐지만, 충돌이 발생하면 그 특정 경우에 한해 8자리 코드로 확장하여 저장할 수도 있다. 즉 평소엔 7글자 쓰다가 충돌나면 8글자로 구분하는 방법인데, 구현이 다소 복잡해지고 일관성이 떨어질 수 있다. (일반적으로 잘 쓰이진 않는다. 또한 현재 7자리로 압축하는 요구사항에도 맞지 않는다.)
- 다른 해시 알고리즘 사용: 기본으로 MD5를 쓰다가 충돌이 발생한 경우 SHA-1 등 다른 해시 알고리즘으로 생성해보는 방법도 생각해볼 수 있다. 그러나 이것도 별로 효율적이지 않으며 거의 쓰지 않는다. 차라리 재시도 로직이 간단하다.
가장 현실적인 방법은 중복 체크 후 재시도이다. 이를 구현할 때, 데이터베이스에 ShortCode 컬럼에 UNIQUE 제약이 걸려 있으므로, 동시에 동일 코드가 들어오면 한 쪽은 삽입 실패할 것이다. 애플리케이션 레벨에서 먼저 select로 확인하는 것도 좋지만, 멀티스레드 환경에서는 DB 수준 unique 제약으로 한 번 더 잡아주는 것이 안전하다. 충돌 시 해당 트랜잭션을 롤백하고 입력을 달리하여(예: salt 추가) 다시 해시 -> 코드 생성 -> 삽입을 시도한다. 이러한 충돌 대응은 해시 공간 대비 사용량이 적을 땐 거의 일어나지 않지만, 시스템이 처리하는 URL 수가 많아질수록 무시 못할 이벤트가 되므로 코드로 고려해야 한다.
해시 기반 솔루션의 장점은 분산 환경에서 서로 다른 노드 간에 별도 조율 없이도 고유 코드 생성 가능하다는 점이다. 그러나 단점으로 꼽은 충돌 가능성과, 또 하나 코드 예측 불가능이라 좋지만 의도적으로 중복 허용이 안됨(다른 입력이라도 같은 출력이 나올 수 있음)이라는 점이 있다. 관리 측면에서도, 만들어진 short_code 자체에 의미가 없어서 (랜덤성) 나중에 이를 역으로 원본을 찾는 건 DB조회 외 방법이 없다.
요약하면, 해시 기반 접근은 구현 난이도는 낮고 성능도 좋지만 (충돌 처리 제외), 충돌 관리와 약간의 비결정론적 요소를 신경 써야 한다. 이러한 이유로 업계에서는 두 번째 방법인 카운터 기반 접근을 많이 선호한다. 이를 이어서 살펴보자.
카운터 기반 솔루션
카운터 기반 방법은 전역에서 증분되는 카운터(일련번호)를 활용하여 단축 URL을 생성하는 방식이다. 쉽게 말해 1부터 시작하는 증가하는 정수를 발급받아 Base62로 변환하고 코드로 사용하는 것이다. 이 접근은 해시 충돌 문제를 원천 회피할 수 있고, 구현도 직관적이다. 하지만 동시성 처리 측면에서 전역 카운터 관리가 필요하고, 잘못 설계하면 병목이나 단일 장애점이 될 수 있다.
카운터를 사용한 Base62 ID 생성 방식
가장 단순한 카운터 기반 흐름은 다음과 같다
- 전역 카운터 값 획득: 새로운 URL 단축 요청이 오면, 현재 카운터 값을 1 증가시켜 고유한 숫자 ID를 하나 확보한다. 예를 들어 처음 요청엔 1, 다음엔 2, ... 이런 식으로 증가.
- Base62 인코딩: 확보한 정수 ID를 Base62로 변환하여 단축 코드 문자열을 얻는다. 예: 1 -> 1, 61 -> z, 62 -> 10, 238327 -> zzz 등의 규칙으로 변환된다.
- DB 저장 및 반환: 이 코드를 키로 원본 URL과 함께 DB에 저장하고, 사용자에게 단축 URL을 반환한다.
이 방법의 큰 장점은 발급되는 ID가 절대 중복되지 않는다는 점이다. 한 번 쓴 숫자는 다시 안 쓰고 계속 증가만 하므로 충돌을 걱정하지 않아도 된다. 또한 해시 계산에 비해 연산이 단순해서 성능도 매우 빠르다(증가 연산 + 진법 변환 정도). 구현하기에도 비교적 명확하다.
예를 들어, 처음 3개의 URL이 들어오면 카운터 값 1, 2, 3을 차례로 배정받고, Base62로 각각 1, 2, 3과 같이 변환되어 short code가 될 수 있다. 이후 61번째 URL의 short code는 z, 62번째는 10 (2자리)로 늘어날 것이다. 결국 n번째 만들어진 URL은 Base62로 표현한 n에 대응된다. (일반적으로는 아주 초기에 생성된 URL들은 자리수가 짧을 수 있지만, 서비스상 굳이 모든 코드의 자릿수를 맞출 필요는 없다. 대부분 서비스들은 4~7자리 등 가변적으로 시작해서 점차 길어지는 방식을 채택한다. 특정 길이로 고정하고 싶다면 카운터를 해당 범위부터 시작하는 기법도 있다.)
카운터 기반의 한 가지 잠재적 단점은 생성되는 코드들이 예측 가능해진다는 것이다. 순차적으로 증가하기 때문에, 어떤 단축 URL이 abc123 다음에는 그 다음 번호에 해당하는 코드가 나올 것이고, 악의적인 사용자가 이를 유추하여 존재하는지 시험해볼 수 있다. 다만 Base62로 섞이기 때문에 코드상의 연속성이 사람에게 명확히 보이진 않을 수 있지만, 어쨌든 전체적으로 번호 순서임에는 변함이 없다. 이를 보완하기 위해 후술할 분산 환경에서는 카운터에 약간의 랜덤 비트를 추가하여 순서를 섞는 방법도 있다.
전역 카운터를 관리하는 방법은 여러 가지가 있다. 간단하게는 데이터베이스의 AUTO_INCREMENT 기능을 사용하는 것이다. 단축 URL 테이블의 기본키를 AUTO_INCREMENT로 두고 삽입하면 DB가 알아서 1씩 증가하는 ID를 발급해준다. 그 ID를 가져와 Base62로 변환하면 된다. 또는 별도의 카운터 전용 테이블을 두고 거기서 값을 읽고 +1 업데이트하는 방법도 있지만, 동시성 제어를 위해 locking이 필요하므로 그보다는 AUTO_INCREMENT PK 활용이 편리하다. 관계형 DB 없이 구현한다면, Redis의 원자적 INCR 명령으로 카운터를 관리하는 방법도 있다. 중요한 것은 여러 애플리케이션 서버들이 이 값을 일관되게 공유해야 하므로, 중앙에서 관리되는 카운터가 필요하다는 점이다.
단일 장애점(SPOF) 문제와 분산 카운터로의 확장
카운터 기반 접근의 단순함 뒤에는 중앙 집중식 관리에 따른 위험이 있다. 모든 단축 URL 생성 요청이 하나의 전역 카운터에 의존하면, 그 카운터가 고장났을 때 전체 서비스가 새 URL을 발급하지 못하게 된다. 예를 들어 DB의 AUTO_INCREMENT를 썼다면 DB 다운 시 생성 기능이 멈춘다. Redis를 한 대 썼다면 그것이 죽으면 역시 안 된다. 즉, Single Point of Failure (SPOF)가 될 수 있다. 또한 생성 요청이 폭주하면 한 곳에 몰리기 때문에 병목 현상이 나타날 수도 있다. 이를 해결하려면 분산 카운터 또는 다중 카운터 체계를 도입해야 한다.
분산 환경에서 고유한 카운터 값을 생성하는 방법으로는 여러 가지 전략이 있다
- ID 구간 분할 할당: 중앙에서 미리 일정 범위의 숫자 블록을 각 애플리케이션 서버에 할당해주는 방법이다. 예를 들어 서버 A에게 1~1백만, 서버 B에게 1백만+1 ~ 2백만 등의 범위를 선분할한다. 각 서버는 자기에게 할당된 범위 내에서 로컬 카운터를 운용하므로, 충돌 없이 병렬로 ID를 발급할 수 있다. 만약 한 서버가 할당량을 다 쓰면 중앙에서 새로운 범위를 요청받아 할당하면 된다. 이 방법으로 한 서버에 장애가 생겨도 그 서버에 할당되었던 범위(예: 1백만개 중 일부 미사용분)는 유실되지만, 총 풀이 워낙 크기 때문에 큰 문제는 아니다. 중요한 것은 한 범위는 오직 한 노드만 쓰도록 관리하여 중복이 없게 하는 것이다.
- 서버 ID와 조합한 다중 카운터: 각 서버에 고유 ID를 부여하고, 생성되는 숫자에 서버ID를 붙이거나 숫자를 혼합하여 고유값을 만드는 방법도 있다. 예를 들어 3대 서버라면, 카운터를 3씩 증가시키되 서버마다 시작 오프셋을 달리하는 방식(서버1은 1,4,7..., 서버2는 2,5,8..., 서버3은 3,6,9,... 식으로) 운용할 수 있다. 이러면 자연스럽게 겹치지 않게 되지만, 서버 증감 시 알고리즘 변경이 필요하고 범위가 골고루 안 나뉘는 단점이 있다.
- Snowflake 알고리즘 등을 사용하는 방법: Twitter의 Snowflake처럼 시간 기반 + 노드ID + 일련번호를 조합해 전역 고유 ID를 생성하는 알고리즘을 사용할 수도 있다. 이 경우 특정 중앙 서버 없이도 각 노드가 고유 ID를 만들어낸다. 다만 구현이 복잡하고, 62진수로 변환하면 길이가 길어질 수 있다.
위 방법들 중 범위 할당 전략은 구현이 비교적 간단하고 효율적이다. 이 방식을 중앙에서 안전하게 처리하려면 분산 조율자(distributed coordinator)가 필요하다. 중앙 역할을 하는 프로세스 자체가 장애에 강하도록 하기 위해, 일반적으로 Apache ZooKeeper 같은 솔루션을 사용한다. ZooKeeper는 여러 서버들로 구성된 고가용성 코디네이터로, 분산 서버들의 상태 관리, 리더 선출, 설정 저장 등에 쓰인다.
이 글의 경우 ZooKeeper를 활용하여
- 서버 노드 등록/탈퇴 감지: 새로운 애플리케이션 서버 인스턴스가 올라오면 ZooKeeper에 자신을 등록하고, 내려가면 지워진다.
- ID 범위 할당 및 추적: ZooKeeper는 현재까지 할당된 전역 카운터의 범위들을 기록하고, 새로 등록된 서버에 겹치지 않는 새로운 범위를 할당해준다. 예를 들어 “서버3에게 3백만~4백만 번 할당” 이런 식이다. 할당된 범위는 ZooKeeper의 znode 등에 “사용 중”으로 마킹하여 두 번 다시 다른 노드에 주지 않는다
- 범위 소진 관리: 애플리케이션 서버가 자신의 범위를 거의 다 쓰면(예: 몇 천 개 남음) ZooKeeper에 다음 범위 요청을 해서 이어서 발급받는다. 이 역시 중앙 조율자가 충돌 없이 처리해준다.
- 장애 허용: 어떤 서버가 죽더라도 그 서버에 할당됐던 범위의 ID들은 비록 모두 쓰지 않았어도 영구히 묵살한다. 그 범위를 다른 서버에 다시 주지 않으므로, 이미 쓰인 ID와 겹칠 일은 없다. 버려지는 ID 수는 일부이므로 전체 3.5조 풀에 비교하면 무시해도 될 정도다.
- 리더 선출 (선택 사항): 여러 애플리케이션 서버 중 특별한 역할(예: 통계 집계나 관리자)을 하나 정해야 하면 ZooKeeper가 leader election도 지원한다. (ID 발급에는 필요 없지만, 혹시 중앙 ID할당 서비스를 이중화한다면 쓸 수 있다.)
등의 기능을 사용할 수 있다. 카운터 기반 시스템에서도 단일 장애점 없이 각 서버가 병렬로 안전하게 ID를 발급할 수 있는 것이다. ZooKeeper 자신도 다중 노드로 구성되어 있기 때문에 한 노드 장애 시에도 동작하며, 쿼럼 메커니즘으로 신뢰성을 보장한다. 결국 전역 일관된 카운터를 분산환경에서 달성하여 충돌 없는 단축 코드 생성을 구현할 수 있다.
정리하면, 카운터 기반 솔루션은 고유ID 보장과 단순성 때문에 많이 쓰이며, 이를 분산환경에서 확장하기 위해 범위할당 + ZooKeeper와 같은 접근을 활용한다. 이러한 구조에서는 생성 작업의 병목이 제거되고, 각 노드가 할당받은 ID로 처리하므로 확장성이 높다.
Apache ZooKeeper를 통한 동시성 문제 해결
앞서 카운터 기반 방식에서 소개한 ZooKeeper 활용은, 동시성 문제를 해결하는 핵심 열쇠이다. ZooKeeper에 대해 부연 설명하자면, Apache ZooKeeper는 분산 어플리케이션들을 지원하기 위한 중앙 집중형 서비스로, 주로 컨피그 관리, 이름 등록, 분산 락, 리더 선출 등의 기능을 제공한다. 우리의 URL Shortener 시스템에서는 주로 분산 락/카운터 관리 역할로 사용된다.
여러 서버가 동시에 새로운 ID를 발급받으려 하면, 자칫하면 중복 ID 생성이나 경쟁 상태(race condition)가 발생할 수 있다. ZooKeeper는 이를 방지하기 위해 원자적 업데이트와 일관성 보장을 제공한다.
예를 들어 "현재 사용 가능한 다음 ID"를 증가시키는 연산을 ZooKeeper 상에서 수행하면, 어떤 순간에도 한 서버만 그 연산을 성공하도록 직렬화된다. 하지만 앞서 설명한 것처럼, 매번 중앙에서 하나씩 증가시키면 성능에 한계가 있으므로, 한 번에 범위 뭉치를 할당하는 방식으로 최적화한 것이다.
ZooKeeper를 도입함으로써 얻게 되는 이점들을 요약하면
- 유일한 ID 보장: 어떤 경우에도 두 서버가 같은 단축 ID를 발급하는 일이 없도록 보장한다. (중앙에서 조율하므로)
- 높은 가용성: ZooKeeper 자체가 다중화되어 있어 고가용성을 지니며, 한 노드 장애 시에도 서비스 가능하다. 따라서 ID 발급 기능이 멈추지 않는다.
- 자동화된 노드 관리: 관리자가 수동으로 서버별 범위를 분배하거나 조정할 필요 없이, ZooKeeper가 자동으로 신규 노드에 ID범위 할당, 노드 다운 시 범위 폐기 등을 수행한다. 운영의 편의성이 높아진다.
- 일관성있는 설정 저장: 단축 URL 서비스 외에도, ZooKeeper를 통해 각 노드가 공유해야 하는 설정 정보나 블랙리스트 URL 등의 데이터를 저장/배포할 수도 있다.
- 확장 용이성: 서버 인스턴스를 늘리면 ZooKeeper가 알아서 등록을 받고 ID 범위를 부여하므로, 수평 확장 시 충돌 걱정 없이 노드를 추가할 수 있다.
결과적으로 ZooKeeper를 활용한 아키텍처에서는 모든 구성요소가 분산되어 동작하면서도 중앙 조율자를 통해 일관성을 유지한다. 단축 URL 생성은 각 앱 서버가 맡고, ZooKeeper는 보이지 않는 곳에서 고유 ID 발급을 뒷받침해준다. 이렇게 하면 해시 기반의 단점이던 충돌 위험도 없애고, 카운터 기반의 단점이던 중앙 집중 병목도 해결하여, 높은 성능과 안정성을 갖춘 URL Shortening 시스템을 구축할 수 있다.