
개요
기존에 20초 이상 걸리는 보고서 쿼리가 있었다. 해당 쿼리는 스프링 어플리케이션에서 native 쿼리를 사용하여 원시 통계 테이블을 조회한 후 보고서 형식에 맞게 반환해주는 코드였다. admin 페이지 특성 상 BtoC 프로덕트 보다는 성능 이슈가 덜하지만 개선할 수 있는 여지가 있어 이를 개선하였다.
내용
내가 생각하는 가장 큰 원인은 두 가지였다. 첫번째는 원시 통계 테이블을 그대로 조회한다는 것이었고, 두번째는 계층 구조의 이점을 살리지 못한다는 것이 그것이다.
기존의 구조, 원시 통계 테이블 참조
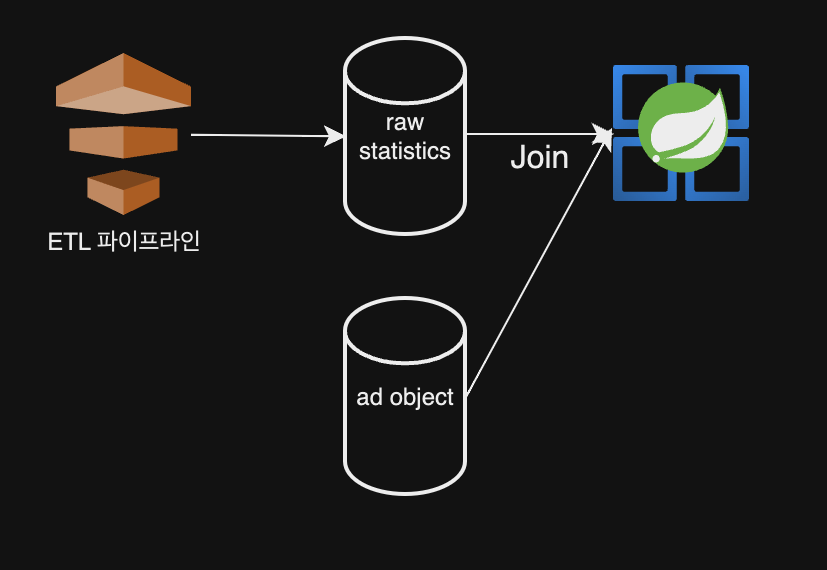
원시 통계 테이블을 참조했을 때 발생하는 가장 큰 이슈는 쿼리를 날렸을 때 스캔해야 할 row 수가 너무 많다는 것이다.(조회 기준이 따라 다르지만 수천만 ~ 수억건이 될 수 있다) 이렇게 데이터를 agg 하는 역할을 굳이 매 쿼리단에서 해줄 이유가 없었다. 즉 배치나 여러 방법을 통하여 미리 집계를 수행하여 1차 가공 테이블을 만들고, 이 테이블을 조회하면 절대적으로 조회해야 할 row수를 대폭 줄일 수 있는 것이다.
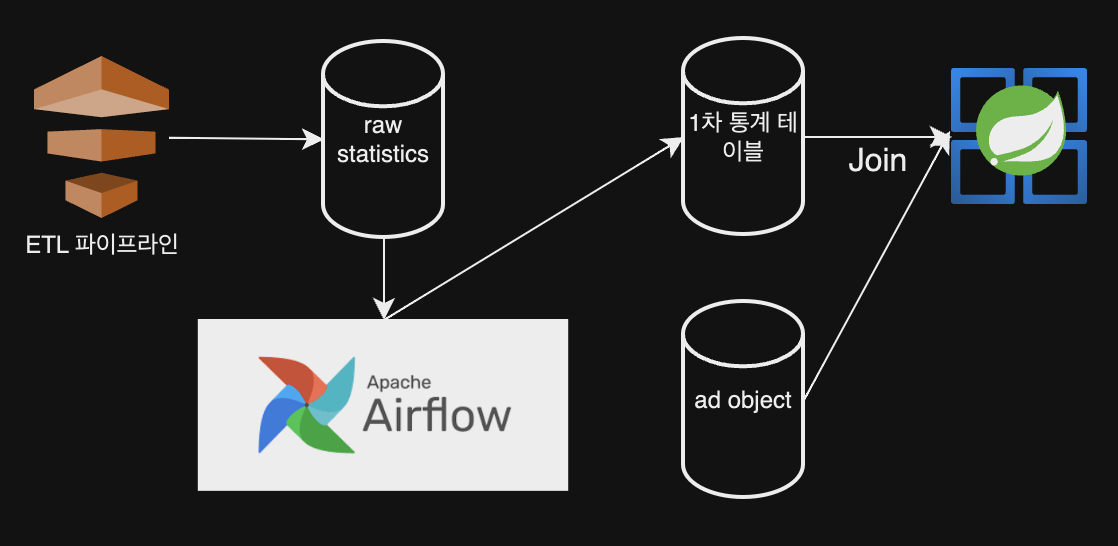
이렇게 Airflow를 사용하여 원시 테이블을 집계하는 dag를 만들어 1차 가공 테이블에 특정 주기로 쌓아주면, 스프링 어플리케이션은 비교적 데이터 수가 적은 1차 가공 테이블을 참조하여 보고서 조회 쿼리를 날릴 수 있다.
이를 통해 평균 20초 이상 걸리던 보고서 쿼리를 1~2초로 단축하였다.
추가 개발 사항 1 NoOffset으로의 전환
기존 페이징 방식이 offset과 limit를 기반으로 개발되어 있었다. 이렇게 되었을 경우, 전체 페이징 수를 보여주는 UX를 구성할 수 있지만, 사용자 입장에서 전체 페이징 수가 무의미하다고 판단되었다.
개발 관점에서 offset이 10만이고, limit가 10이라면 실질적으로 사용되는 행 수는 10개 뿐이지만, 조회 자체는 10만 10개를 조회해야 하는 성능 문제가 있다.
SELECT *
FROM table
ORDER BY id
LIMIT 10 OFFSET 100000;
따라서 Offset을 없애고 where절로 핸들링하면 검색하는 row수를 대폭 줄일 수 있다.
# 첫번째 페이지
SELECT *
FROM table
WHERE id > 0
ORDER BY id
LIMIT 10;
# 두번째 페이지
SELECT *
FROM table
WHERE id > 10
ORDER BY id
LIMIT 10;
# 세번째 페이지
SELECT *
FROM table
WHERE id > 20
ORDER BY id
LIMIT 10;개요
기존에 20초 이상 걸리는 보고서 쿼리가 있었다. 해당 쿼리는 스프링 어플리케이션에서 native 쿼리를 사용하여 원시 통계 테이블을 조회한 후 보고서 형식에 맞게 반환해주는 코드였다. admin 페이지 특성 상 BtoC 프로덕트 보다는 성능 이슈가 덜하지만 개선할 수 있는 여지가 있어 이를 개선하였다.
내용
내가 생각하는 가장 큰 원인은 두 가지였다. 첫번째는 원시 통계 테이블을 그대로 조회한다는 것이었고, 두번째는 계층 구조의 이점을 살리지 못한다는 것이 그것이다.
기존의 구조, 원시 통계 테이블 참조
원시 통계 테이블을 참조했을 때 발생하는 가장 큰 이슈는 쿼리를 날렸을 때 스캔해야 할 row 수가 너무 많다는 것이다.(조회 기준이 따라 다르지만 수천만 ~ 수억건이 될 수 있다) 이렇게 데이터를 agg 하는 역할을 굳이 매 쿼리단에서 해줄 이유가 없었다. 즉 배치나 여러 방법을 통하여 미리 집계를 수행하여 1차 가공 테이블을 만들고, 이 테이블을 조회하면 절대적으로 조회해야 할 row수를 대폭 줄일 수 있는 것이다.
이렇게 Airflow를 사용하여 원시 테이블을 집계하는 dag를 만들어 1차 가공 테이블에 특정 주기로 쌓아주면, 스프링 어플리케이션은 비교적 데이터 수가 적은 1차 가공 테이블을 참조하여 보고서 조회 쿼리를 날릴 수 있다.
이를 통해 평균 20초 이상 걸리던 보고서 쿼리를 1~2초로 단축하였다.
추가 개발 사항 1 NoOffset으로의 전환
기존 페이징 방식이 offset과 limit를 기반으로 개발되어 있었다. 이렇게 되었을 경우, 전체 페이징 수를 보여주는 UX를 구성할 수 있지만, 사용자 입장에서 전체 페이징 수가 무의미하다고 판단되었다.
개발 관점에서 offset이 10만이고, limit가 10이라면 실질적으로 사용되는 행 수는 10개 뿐이지만, 조회 자체는 10만 10개를 조회해야 하는 성능 문제가 있다.
SELECT *
FROM table
ORDER BY id
LIMIT 10 OFFSET 100000;
따라서 Offset을 없애고 where절로 핸들링하면 검색하는 row수를 대폭 줄일 수 있다.
# 첫번째 페이지
SELECT *
FROM table
WHERE id > 0
ORDER BY id
LIMIT 10;
# 두번째 페이지
SELECT *
FROM table
WHERE id > 10
ORDER BY id
LIMIT 10;
# 세번째 페이지
SELECT *
FROM table
WHERE id > 20
ORDER BY id
LIMIT 10;